GoogleのMobileDiffusionは、スマートフォンでのテキストから画像への生成における Google の最新開発です。
スマートフォン向けに特別に設計されたこの普及モデルは、テキスト入力から 1 秒以内に高品質の画像を生成します。
はじめに
視覚的なコンテンツが主導する現代において、テキストから画像を迅速かつ効果的に生成する必要性はますます明らかになっています。GoogleのMobileDiffusionは、特にモバイルデバイス上でのテキストから画像生成の方法を革新し、その分野においてゲームチェンジャーとなる可能性があります。
MobileDiffusionのかんたんな概要
MobileDiffusionは、スマートフォン上での高速かつ高品質な画像生成を目指すGoogleの最新開発です。
文字入力からわずかな秒数で高品質な画像を生成するディフュージョンモデルとしてデザインされています。
モバイルデバイス向けに開発されたこのモデルは、たった5億2000万のパラメータしかないという点で、Stable DiffusionやSDXLのような数十億のパラメータを持つ他のモデルと比べて著しく小さいです。これにより、モバイルデバイスでの利用がより適しています。
研究者たちのテストによれば、MobileDiffusionはAndroidスマートフォンとiPhoneの両方で、512 x 512ピクセルの解像度の画像を約半秒(1秒以下)で生成できます。その出力は、入力するたびに継続的に更新されます。Googleのデモ動画で示されている通りです。
MobileDiffusionの主な構成要素
MobileDiffusionは、テキストエンコーダ、ディフュージョンネットワーク、および画像デコーダの3つの主要なコンポーネントで構成されています。
UNetには、テキスト理解に重要なセルフ アテンション レイヤー、クロス アテンション レイヤー、およびフィードフォワード レイヤーが含まれています。しかし、この層のアーキテクチャは計算的に複雑でリソースを多く必要とします。GoogleはUViTアーキテクチャを使用し、UNetの低次元領域により多くのトランスフォーマーブロックを配置してリソース要件を削減しています。
さらに、蒸留とGenerative Adversarial Network(GAN)のハイブリッドが、1から8のレベルのサンプリングに使用されています。
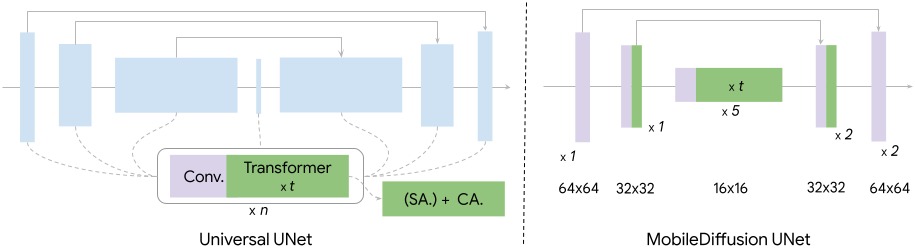
高解像度ではセルフアテンションレイヤーをスキップします。| 画像:Google
モデルの一般化の可能性について
現時点では、Googleはこのモデルを無償で提供しておらず、提供する計画も発表していません。
むしろ、この研究はモバイルデバイスでのテキストから画像生成を一般化する目標に向けた一歩と考えられています。
GoogleはPixelシリーズという独自のスマートフォンファミリーを所有しており、
Pixelシリーズではハードウェアとソフトウェアの両方で生成AIがますます重要なトピックとなっています。
画像生成の進化
昨年、QualcommはStable Diffusionに基づく画像生成が可能なことをデモンストレーションしました。
その際、ハイスペックなAndroidスマートフォン上での画像生成が可能となり、当時としては驚異的な技術進歩でした。
ただし、512 x 512ピクセルの画像を生成するには20回の推論ステップで約15秒かかりました。
GoogleのMobileDiffusionは、オペレーティングシステムに依存せず、すべてのシステムで迅速な結果を提供します。
特にiPhone 15 Proでは、Galaxy S24(GoogleのAndroidを実行する最新のフラッグシップ)よりもさらに優れています。
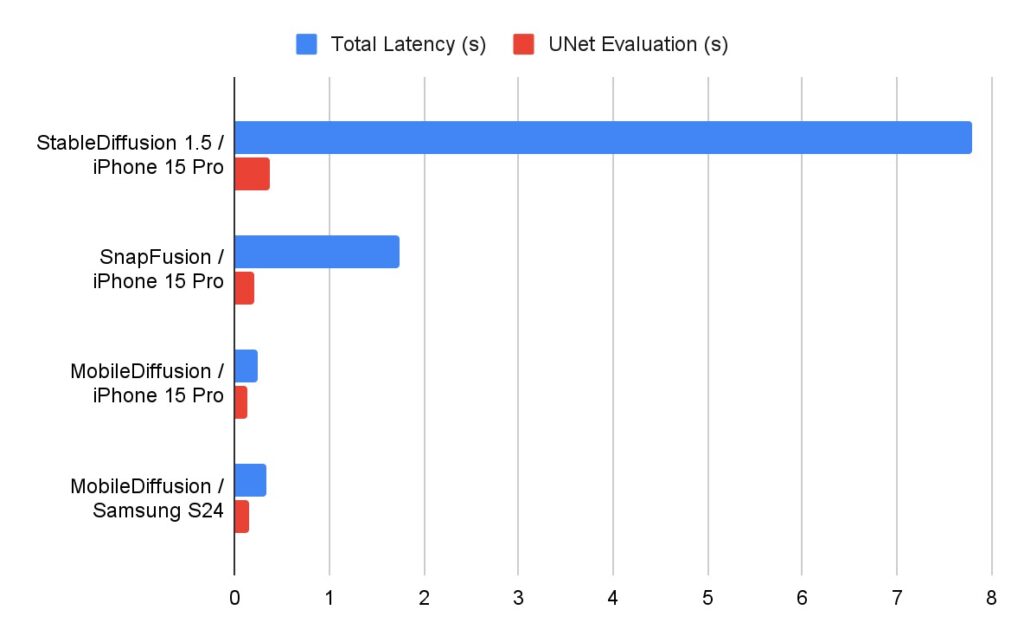
他のモデルとの比較
近年では、SDXL TurboやPixArt-δも強力なシステム上での準リアルタイムの画像生成において重要な進展を遂げています。ただし、これらの進歩はより強力なシステムに焦点を当てています。
まとめ
Googleが開発したMobileDiffusionは、スマートフォン上での効率的なテキストから画像生成モデルです。モデルサイズがわずか520億のパラメータであるため、非常にコンパクトであり、モバイルデバイスでの利用に最適です。Googleのテストによれば、AndroidとiPhoneデバイスで迅速な結果が得られており、その出力はテキスト入力中に継続的に更新されます。MobileDiffusion は、テキスト エンコーダ、拡散 UNet、および画像デコーダを備えた UNet アーキテクチャを使用して、リソース要件を削減し、高速な画像生成を可能にします