ChatGPTを使う前におさえておきたい基礎知識
『ChatGPT』とは、人工知能の研究機関であるOpenAI社が開発したAIチャットサービスです。
文字の関連性、単語間の関連性、感情などの要素との関連性をもとに
言葉を要素にばらし、要素間の関連性のみ理解するため言葉の”意味”は理解できないのが特徴です。
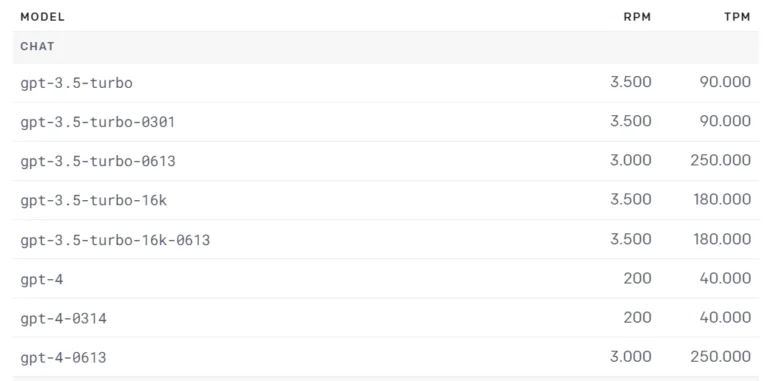
最新モデルは『GPT-4-0613』および『GPT-3.5-turbo-0613』
『GPT-4』はOpenAIが開発した最新の言語モデルです。
GPT-4に搭載される大規模言語モデル(LLM:LargeLanguageModels)は
GPT-3に比べてさらに高度な自然言語処理能力を持っており
幅広いタスクにおいて優れたパフォーマンスを発揮しています。
GPT4よりも古いバージョンのGPT3.5やGPT3は無料で利用できましたが、GPT4は有償となります。
GPT4を利用するには、ChatGPTの有料プランである「ChatGPT Plus」の契約が必要です。
GPT-3は、2020年9月にマイクロソフトのクラウドサービス「Microsoft Azure」上で利用可能なAPIとして公開され
その後、OpenAI社がGPT3の改良版であるGPT3.5を開発して、ChatGPTが誕生します。
2019年に「GPT-2」2022年に「ChatGPT-3」そして2023年3月にGPT4が誕生し、
今回、2023年6月に最新モデル「GPT-4-0613」が発表されました。
それぞれの訓練データ量については膨大な進化を遂げています。
GPT4とGPT3.5の違いは、次の3点です。
回答の精度はGPT3.5よりもGPT4が優れている
司法試験や各種の大学試験などでGPT3.5以上にGPT4が成果をあげている
GPT4は画像の内容を解析できるマルチモーダル機能が備わっている。
それぞれの違いについてご説明します。
一つ目の違いは、指示や質問に対する回答・生成の精度です。
開発元のOpenAI社が公表しているレポートを見ると、
英語で質問を与えたときに得られる回答の精度は、GPT3.5よりもGPT4の方が優れています。
また、司法試験や各種の大学試験などでもGPT3.5以上にGPT4の方が成果をあげています。
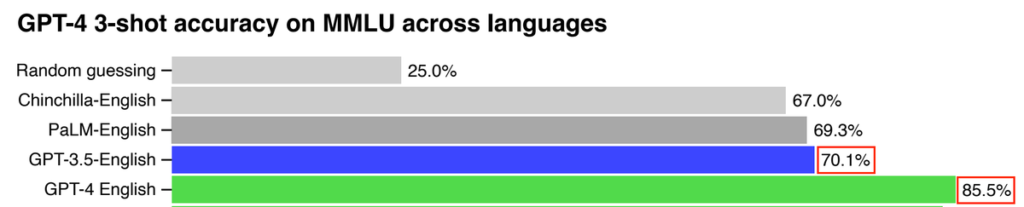
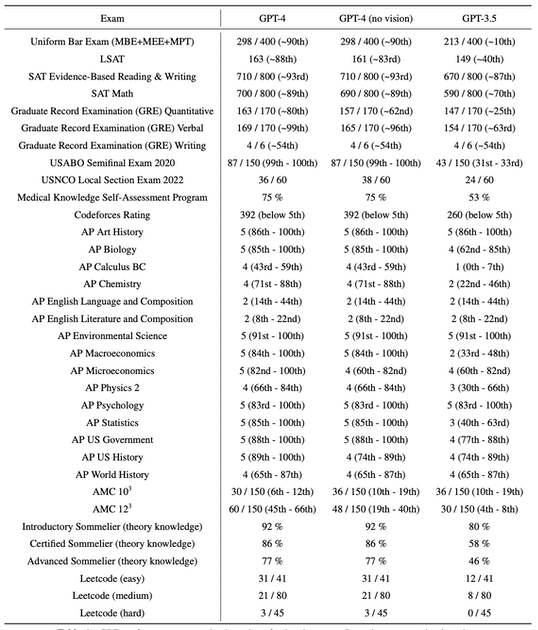
GPT4では、模擬司法試験で受験者の上位10%に入るスコアを出しました。
一方GPT3.5では、下位10%に入るスコアに留まっています。
二つ目の違いはGPT-4は、トークン数がGPT-3.5に比べて大幅に増加しています。
| 比較項目 | GPT-3.5 | GPT-4 |
| パラメーター数(精度) | 約1.75兆個 | 約100兆個(推定) |
| 機能 | 自然言語生成による文書作成 | 自然言語生成による文書作成 画像入力による文章生成 画像・音楽・動画の生成 |
| 最大トークン数 | 2,048(5,000文字) | 32,768(約25,000文字) |
| 利用方法 | OpenAIが提供するAPIを通じて利用 チャットGPTで利用 | OpenAIが提供するAPIを通じて利用 チャットGPTで利用 ※MicrosoftBingで搭載済み |
| データセット | ネット上のテキストデータ | ネット上のテキストデータ、画像データ、音声データ |
| 学習方法 | 教師なし学習 | 教師なし学習、教師あり学習 |
| 能力 | テキスト生成 | テキスト生成、画像生成、音声生成 |
| ユーザーインターフェース | テキストベース | テキストベース、画像ベース、音声ベース |
| ユーザー体験 | テキストのみの対話 | マルチモーダルな対話(テキスト、画像、音声) |
| パフォーマンス | 高い | より高い |
| 応用範囲 | テキスト生成、対話システム | テキスト生成、対話システム、画像生成、音声生成 |
GPT-4はより進化したアーキテクチャと学習方法を採用しているため
これにより、多くのテキストデータを学習し、さらに広範囲な知識と文脈を持つことで
より高度な自然言語処理タスクに対して回答の精度が格段に上がっていることが分かります。
三つ目の違いは、GPT-4は、画像内容を解析できることです、
GPT-4では新たに、画像の内容を解析できるマルチモーダル機能に対応しました。

OpenAIは、米国の掲示板サイト「Reddit」から引用した、エレコムの「ケーブルマニア」という商品について3枚の画像をコラージュしたものをGPT-4に入力し、「この画像の何が面白いの? パネル順に説明して」(What is funny about this image? Describe it panel by panel.)と命令した例を提示。GPT-4はこんな答えを返しました。
「この画像の面白いところは、モダンなスマホの小さな充電端子に、大きくて時代遅れなVGA端子を差し込むというばかげたところから来ています」
ChatGPT
この結果から、GPT-4は、GPT-3.5にはない画像の情報を理解し、おかしな箇所を正確に指摘できる事を証明しました。ただし、このGPT-4の画像解析機能はまだ研究段階で、一般公開はされていません。
GPT-4-0613とGPT-3.5-turbo-0613=の違いは? GPT-4-0613は何が変わった?
GPT-4-0613=関数呼び出しが使える改良モデル
外部のツールやAPIと確実に連携できるように!
LangChainのOutputParserがOpenAI APIに実装されたイメージ。
出力するJSONフォーマットを指定できるようにファインチューイングされたモデル。
このアプデは新モデルのGPT-4-0613とGPT-3.5-turbo-0613で使うことができます。
GPT-3.5-turbo-0613=関数呼び出しが使えるGPT-3.5-turboの改良モデル
「関数呼び出し(function calling)」では、モデルが関数を呼び出すための引数を含む
JSONオブジェクトを出力できるようになり、GPTの機能を外部のツールやAPIから使いやすくなりました。
GPT-3.5-turbo-16k=従来よりはコンテキスト長4k だったが4倍に
→過去の会話や記憶を保持できることで一貫した会話が可能
※Playgroundでは使うことができていました。
このアップデートは新モデルのGPT-4-0613とGPT-3.5-turbo-0613で使用可能です。
英語と日本語における入出力の違いは?OpenAI 最新アップデート

ChatGPTなどのAIでは、文章を読み書きするときに『トークン』という単位で処理し
入出力合わせて最大で約4,000トークンしか扱えない仕様になっています。
英語では1ワード=1トークンとしてカウントしますが、
日本語の場合は1文字=1トークンとしてカウントされます。
また、日本時間6/14 2時ごろに OpenAI から
最新アップデートが公開されました
https://openai.com/blog/function-calling-and-other-api-updates
引用元:Function calling and other API updates
ChatGPTの最新モデルの料金は?気になる変更点
・Embeddings(最も人気のある埋め込みモデル)
text-embedding-ada-002 が従来より75%安く
$0.0001 / 1K token
・GPT-3.5-turbo
入力のトークンコストが25%安く
入力:$0.0015 / 1 token
出力:$0.002 / 1K token
・GPT-3.5-turbo-16k
入力:$0.003 / 1K token
出力:$0.004 / 1K token
従来のコンテクスト長4k のモデルよりも2倍の値段設定
詳細や今後の情報はOpenAIからの発表を待ちましょう。
https://openai.com/blog/function-calling-and-other-api-updates
引用元:Function calling and other API updates
ChatGPTの料金プラン
ChatGPTには主に2つのプランがあります:無料プランと有料プラン(ChatGPT Plus)です。
| プラン | 料金 | 主な特徴 |
|---|---|---|
| 無料プラン | 無料 | 基本的なChatGPTの機能を利用可能 |
| 有料プラン(ChatGPT Plus) | 月額20ドル(2023年5月現在で約2,700円) | 高度な機能と優先的なアクセス権を提供 |
無料プラン
無料プランは、基本的なChatGPTの機能を利用することができます。しかし、一部の高度な機能や優先的なアクセス権は含まれていません。そのため、頻度は少ないですが、日本だと夜間などでアクセス制限となる場合もあります。無料プランは、ChatGPTを試したいユーザーや基本的な用途に使用するユーザーに適しています。
有料プラン(ChatGPT Plus)
ChatGPT Plusは、月額20ドル(2023年7月現在で約2,700円)で提供されています。
このプランでは、無料プランに加えて、一部の高度な機能や優先的なアクセス権が提供されます。
具体的には、ピークタイムでもChatGPTへのアクセスが可能で、応答時間が短縮されます。また、無料プランで使用される言語モデルである「GPT-3.5」よりも高性能な「GPT-4(ChatGPT4)」が利用できたり、Webブラウジングやプラグインなどの新機能や改善への優先的なアクセスも提供されます。
ChatGPT Plusへの支払い方法
ChatGPT Plusの支払い方法は、クレジットカードのみ対応しており、デビットカードやPayPalは利用できません。Visa、MasterCard、American Express、Discover、JCB、Diners Club、の各クレジットカードで支払いが可能です。
なお、ChatGPT Plusの料金は月額制(サブスク)で、自動的に更新されます。サービスを停止する場合は、次の課金日前にキャンセルを行う必要があります。
ChatGPT-4: GPT-4の新機能と品質について
OpenAIはChatGPT Plusの制限を引き上げ、加入者は3時間で最大50メッセージをGPT-4に送信できるようになりました。これにより、ユーザーはより多くのメッセージを送信し、効率的にタスクを実行することができます。
GPT-4の新機能 ※7月21日更新
3月に新しいGPT-4バージョン「0613」が導入されて以降、メッセージ数は2時間で25メッセージに制限されていました。しかし、最近の変更により、ChatGPT Plus加入者は3時間で最大50メッセージを送信できるようになりました。これにより、ユーザーはより柔軟にGPT-4を活用することができます。
GPT-4は、GPT-3からの進化したモデルであり、書き込み速度が大幅に向上しています。これは、GPT-3からGPT-3.5に切り替えた際にも当てはまる特徴です。ただし、速度向上と同時に品質の低下はありませんでした。GPT-4は、より多くのリクエスト数とトークンを処理できるため、大量の情報を迅速かつ効率的に生成できます。
ChatGPT-4の詳細がリーク
OpenAIの最新の言語モデルであるGPT-4の詳細が流出しました。GPT-4はGPT-3の10倍以上のサイズで、専門家の混合モデルを採用しています。また、視覚マルチモーダルな機能も備えています。ここでは、GPT-4の主な特徴とトレーニングコスト、推論コスト、推論アーキテクチャについて説明します。
ChatGPT-4のリークについての詳細はこちらの記事でも紹介しています。
ChatGPT-4のパラメータ数
GPT-4は120層にわたる合計約1.8兆個のパラメーターを持っています。これはGPT-3の10倍以上です。パラメーターのうち約55Bはアテンション用の共有パラメーターで、残りは専門家の混合(MoE)モデルに分散されています。
ChatGPT-4 MoEモデル
MoEモデルとは、モデル内で複数のエキスパートと呼ばれる小さなサブネットワークを利用するものです。各エキスパートはMLPの約111Bのパラメーターを持ちます。各フォワードパスでは、各トークンがどのエキスパートにルーティングされるかが決定されます。OpenAIは16個のエキスパートを使用しており、フォワードパスごとに2個が選択されます。
MoEモデルの利点は、コストを抑えながら大規模なモデルをトレーニングできることです。各フォワードパス推論(1トークンの生成)には約280Bのパラメーターと約560TFLOPしか使用しません。これは純粋に密なモデルでは約1.8兆個のパラメーターと約3,700TFLOPが必要となることと比べて大幅に少ないです。
MoEモデルの欠点は、推論時に扱いにくいことです。エキスパートが休止状態になる可能性があるため、利用率が低下する可能性があります。また、エキスパートの数を増やすと一般化や収束が難しくなる可能性があります。OpenAIはエキスパートの数を控えめにすることでリスクを回避しました。
ChatGPT-4のデータセット
GPT-4は約13T個のトークンで学習されました。これらはエポックも含めてカウントされており、ユニークなトークンではありません。テキストベースのデータは2エポック、コードベースのデータは4エポックで学習されました。また、ScaleAlと内部から数百万行の命令微調整データも使用されました。
ChatGPT-4 32K
GPT-4には32kのコンテキスト長(seqlen)のバージョンもあります。これは事前トレーニング後に8kのバージョンを微調整したものです。事前トレーニング段階では8kのコンテキスト長が使用されました。
ChatGPT-4のバッチサイズ
バッチサイズはクラスタ上で何日もかけて徐々に上げていきましたが、最終的にOpenAIは6000万のバッチサイズを使用しました。これはエキスパートあたり750万トークンのバッチサイズに相当します。しかし、これはすべてのエキスパートがすべてのトークンを見ているわけではないため、実際のバッチサイズはseq lenで割った値になります。
ChatGPT-4の並列化戦略
GPT-4はすべてのA100 GPUで並列化されています。8ウェイテンソル並列と15ウェイパイプライン並列を使用しています。おそらくZeRo Stage 1やブロックレベルのFSDPも使用しています。
GPT-4のトレーニングコスト
OpenAIのGPT-4のトレーニングFLOPSは約2.15e25で、約25,000台のA100を90~100日間、約32~36%のMFUで使用しています。この極端に低い利用率の一部は、再起動が必要なチェックポイントを必要とする不合理な数の障害によるものです。A100時間あたりのコストが約1ドルだとすると、今回のトレーニング費用だけで約6,300万ドルになります。
ChatGPT-4の視覚マルチモーダル
GPT-4にはテキストエンコーダとは別にビジョンエンコーダがあり、クロスアテンションを持ちます。アーキテクチャはFlamingoに似ています。GPT-4の1.8Tの上にさらにパラメーターを追加しています。テキストのみの事前学習後、さらに約2兆個のトークンを使って微調整されます。
このビジョン機能の主な目的のひとつは、ウェブページを読んだり、画像やビデオに写っている内容を書き起こしたりできる自律型エージェントです。彼らが訓練しているデータの中には、共同データ(レンダリングされたLaTeX/テキスト)、ウェブページのスクリーンショット、Youtubeのビデオ:フレームをサンプリングし、Whisperを実行してトランスクリプトを得るものがあります。
ChatGPT-4の投機的デコード
OpenAIはGPT-4の推論で投機的デコードを使っているかもしれません。このアイデアは、より小さな高速モデルを使っていくつかのトークンを事前にデコードし、それらを1つのバッチとして大きなオラクルモデルに送り込むというものです。小さなモデルの予測が正しければ、大きなモデルもそれに同意し、1つのバッチで複数のトークンをデコードできます。しかし、ドラフトモデルが予測したトークンを大きなモデルが拒否した場合、残りのバッチは破棄されます。そして、より大きなモデルで処理を続けます。
新しいGPT-4の品質が劣化したという陰謀説は、単にオラクルモデルに投機的解読モデルからのより低い確率のシーケンスを受け入れさせているからかもしれません。
ChatGPT-4 推論アーキテクチャ
推論は128GPUSのクラスタ上で実行されます。このクラスタは複数のデータセンターに分散しています。8ウェイテンソル並列と16ウェイパイプライン並列で実行されます。8GPUの各ノードのパラメータは、FP16ではGPUあたり30GB以下、FP8/int8では15GB以下の、わずか約130Bしかありません。
モデルは120層あるので、15の異なるノードに収まります。[エンベッディングも計算する必要があるため、最初のノードではレイヤーが少なくなる可能性があります]。
ChatGPT-4の推論コスト
GPT-4の推論コストは、175Bパラメーターの3倍です。Davinchiの3倍かかります。これは、GPT-4に必要なクラスタが大きいことと、達成される利用率がはるかに低いことが主な原因です。
GPT-4の推定コストは、128個のA100で1kトークンあたり0.0049セントです。GPT-4 8k seqlenを128個のH100で推論する場合、1kトークンあたり0.0021セントです。注意すべき点は、高い利用率と高いバッチサイズを想定していることです。
ChatGPT-4のマルチクエリーへの注意
OpenAIは他のチームと同様にMQAを使用しています。そのため、必要なヘッド数は1つだけで、KVキャッシュのメモリ容量は大幅に削減できます。それでも、32k seqlen GPT-4は間違いなく40GBのA100では動作しません。8kは最大bszに上限があります。
ChatGPT-4の連続バッチ処理
OpenAIは、可変バッチサイズと連続バッチの両方を実装しています。これは、推論コストを最適化すると同時に、ある程度の最大レイテンシーを可能にするためです。
以上が流出したGPT-4の詳細です。OpenAIは自分たちがやっていることを知っていますが、それは魔法ではありません。彼らは高品質のデータを得るのに苦労しており、このような大規模なトレーニングでは多くのトレードオフや障害に直面しています。
詳細の真偽は不明ですが、上記リーク情報は以下のサイトから公表されています
https://finance.sina.cn/tech/2023-07-11/detail-imzahsyr4285876.d.html?from=wap