Stable Diffusion 企業である Stability AI は、CarperAIと共に2つの新しい大規模言語モデルを発表しました。
その中の1つがMetaのLlama v2をベースにしており、高いパフォーマンスと迅速なオープンソース開発を実現しています。
簡易まとめ
- FreeWilly1とFreeWilly2は、それぞれ「LLaMA 65B」および「LLaMA 2 70B」を基盤とし、「Supervised Fine-Tune (SFT)」という手法でファインチューニング
- モデルは法律や数学といった専門的な分野において複雑な問題解決能力を持ち、いくつかのタスクではGPT-3.5に匹敵する性能
- 非商用ライセンスにて公開される予定
- Stability AIは、既存の言語モデルを土台にして新たなモデルの開発に取り組んできました。
- このFreeWilly1とFreeWilly2には、高品質な指示を与えられるプロンプトを活用したデータセットが統合されています。
- データセットの構築には、Microsoftが発表した論文「Orca: Progressive Learning from Complex Explanation Traces of GPT-4」を参考にした手法を用いています。
- モデルの性能評価ではEleutherAIの「lm-eval-harness」および「AGIEval」を使用しているとのことです。
新しい言語モデルの概要
フリーウィリー・モデルには、MetaのLlamaモデルをベースにした2つのバージョンがあります。その中でもFreeWilly2は、すでに700億のパラメータを持つ新しいLlama-2モデルを使用しています。FreeWillyチームは、「高品質の指示」で生成された新しい合成データセットを使用した「慎重な微調整」に取り組んでいます。
MicrosoftのOrcaメソッド
FreeWillyチームはMicrosoftの「Orcaメソッド」を活用しています。これは、出力スタイルを単に模倣するのではなく、小さなモデルに大規模な言語モデルの推論プロセスを段階的に教えることを含みます。具体的には、Microsoftの研究者が段階的な推論プロセスを含む、より大きなモデル(この場合はGPT-4)を使用してトレーニングデータセットを作成しました。
1. FreeWillyとFreeWilly2の紹介
- FreeWillyはMetaのLlamaモデルに基づいたものであり、
- FreeWilly2は新しいLlama-2モデルを使って700億のパラメータを持っています。
2. チームの取り組み
- 高品質の指示による新しい合成データセットを使用した慎重な微調整が行われました。
- Microsoftの「Orcaメソッド」を利用して、小さなモデルに大規模な言語モデルの推論プロセスを段階的に教えることが含まれています。
3. 実験の目標
- 大規模なAIモデルと同等の性能を持つ小規模なAIモデルの開発が目指されています。
- Orcaは一部のテストで同サイズのモデルよりも優れたパフォーマンスを示しますが、元のモデルには劣ります。
FreeWillyの性能評価
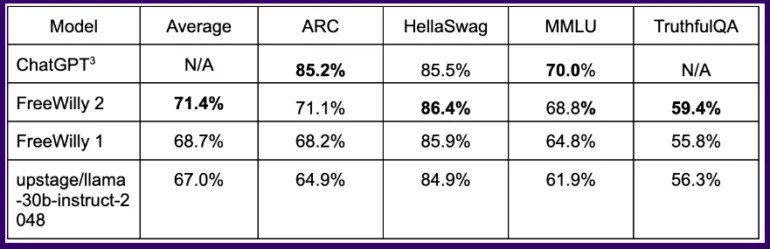
1. ベンチマーク結果
- FreeWillyモデルは一部の論理タスクでChatGPTと同等の結果を達成しました。
- FreeWilly2モデルは明らかにFreeWilly1を上回っています。
2. 改善の余地
- Metaの新しい標準モデルには改善の余地があり、オープンソースコミュニティの活用が期待されます。
- FreeWilly 2は現在、トップパフォーマンスのオープンソースモデルのリストをリードしていますが、オリジナルのLlama 2にはわずかに劣っています。
一般的なベンチマークでは、この方法でトレーニングされたFreeWillyモデルは一部の論理タスクでChatGPTと同等の結果を達成し、Llama 2に基づくFreeWilly 2モデルは明らかにFreeWilly 1を上回っています。すべてのベンチマークの平均で、FreeWilly 2はLlama v2よりも約4ポイント進んでいます。これは、Metaの新しい標準モデルには改善の余地があり、オープンソースコミュニティがその活用を支援できることを初めて示しています。
FreeWillyの利用とダウンロード
- FreeWillyモデルは研究目的のみに開発され、非営利ライセンスに基づいてリリースされています。
- HuggingFaceからダウンロードすることができます。
全体として、FreeWilly 2は現在、トップパフォーマンスのオープンソースモデルのリストをリードしており、重要な一般言語理解ベンチマークMMLUではオリジナルのLlama 2がまだわずかに上回っています。FreeWillyモデルは研究目的のみに開発され、非営利ライセンスに基づいてリリースされています。
FreeWilly1 and FreeWilly2 set a new standard in the field of open access Large Language Models. They both significantly advance research, enhance natural language understanding, and enable complex tasks.
Carper AI, Stability AI
まとめ
Stability AIとCarperAIは2つの新しい大規模言語モデルをリリースしました。FreeWilly2は700億のパラメータを持つMetaのLlama-2モデルに基づいており、「慎重な微調整」を通じて最適化されています。研究チームはマイクロソフトの「Orca」手法を使用して、小規模なAIモデルが推論から学習することで、大規模な言語モデルの機能の一部を得ることができると述べています。FreeWillyモデルは研究に無料で利用でき、自然言語の機械の理解を向上させ、複雑なタスクを可能にし、FreeWilly2はベンチマークで最高の平均結果を出したオープンソースモデルとみなされています。
よくある質問(FAQs)
- FreeWillyモデルを商業目的に使用できますか?
いいえ、FreeWillyモデルは研究目的のみに使用できます。 - FreeWilly2モデルのサイズはどのくらいですか?
FreeWilly2モデルは700億のパラメータを持っています。 - FreeWillyチームが使用したデータセットのサイズは?
FreeWillyチームは約600,000のデータポイントからなるデータセットを使用しました。 - FreeWillyモデルはどのようなタスクに向いていますか?
FreeWillyモデルは自然言語の機械理解に向いており、多様な複雑なタスクに対応できます。 - FreeWillyモデルのダウンロード方法を教えてください。
FreeWillyモデルはHuggingFaceからダウンロードできます。