近年、商用およびオープンソースの生成テキストAIが急速に発展しており、その性能や実用性が注目を集めています。特に、「AgentBench」と呼ばれるテストによると、GPT-4が他の言語モデルを圧倒し、現実世界の実用的なミッションにおいて驚異的な成果を上げていることが明らかになっています。
AgentBenchテストとは?
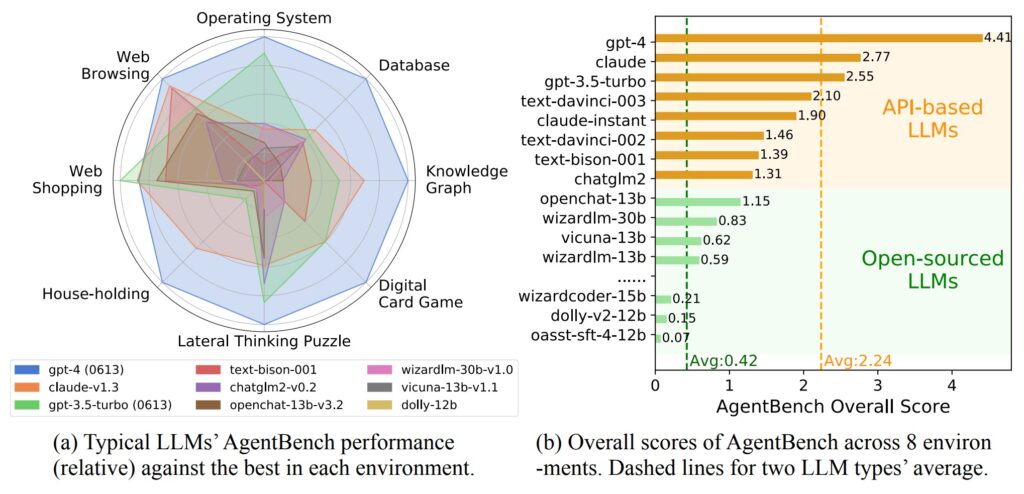
「AgentBench」は、大規模な言語モデルの実用能力を評価するために特別に開発された標準化されたテストです。このテストは、リアルタイムの対話型環境で実施され、大規模な言語モデルがさまざまなタスクをどれだけうまく処理できるかを測定します。このテストにおいてGPT-4は、合計8つの領域で圧倒的な成果を達成しています。
AgentBenchテストによるモデルの比較
研究者たちは、「AgentBench」という特別なテストを用いて、大規模な言語モデルの実用性を測定しました。このテストでは、8つの異なる領域におけるミッションの実行能力が評価されます。それぞれの領域は以下の通りです。
- オペレーティング システム
- データベース
- ナレッジ グラフ
- デジタル カード ゲーム
- 水平思考パズル
- 予算
- インターネット ショッピング
- Web ブラウジング
オペレーティング システム(Operating System)
コンピュータのオペレーティング システムの使用に関連するタスクを実行する能力がテストされます。GPT-4はこれらのタスクにおいても優れたパフォーマンスを見せました。
データベース(Database)
データベースとの連携能力がテストされます。GPT-4は複雑なデータベース関連のタスクを効果的に処理する能力を示しました。
ナレッジ グラフ(Knowledge Graph)
複雑なナレッジ グラフを処理する能力が評価されます。GPT-4は豊富な情報を適切に理解し、利用するスキルを発揮しました。
デジタル カード ゲーム(Digital card game)
デジタル カード ゲームにおいて、戦略を理解し展開する能力がテストされます。GPT-4はゲームに関する知識を駆使して高い戦略を実現しました。
水平思考パズル(Lateral thinking puzzles)
創造的な問題解決能力がテストされます。GPT-4は既存の概念にとらわれず、新たなアプローチで問題に取り組むスキルを発揮しました。
予算(Budgets)
予算内でタスクを処理する能力が評価されます。この領域では実世界の制約を考慮しながら効率的な解決策を提供しました。
インターネット ショッピング(Internet Shopping)
オンライン ショッピング関連のタスクを処理する能力が評価されます。GPT-4は商品検索や購買に関する質問に的確な回答を提供しました。
Web ブラウジング(Web browsing)
インターネットの使用に関連するタスクを実行する能力がテストされます。GPT-4はWeb上の情報を適切に検索し、要約するスキルを持ち合わせています。
AgentBenchテストの結果
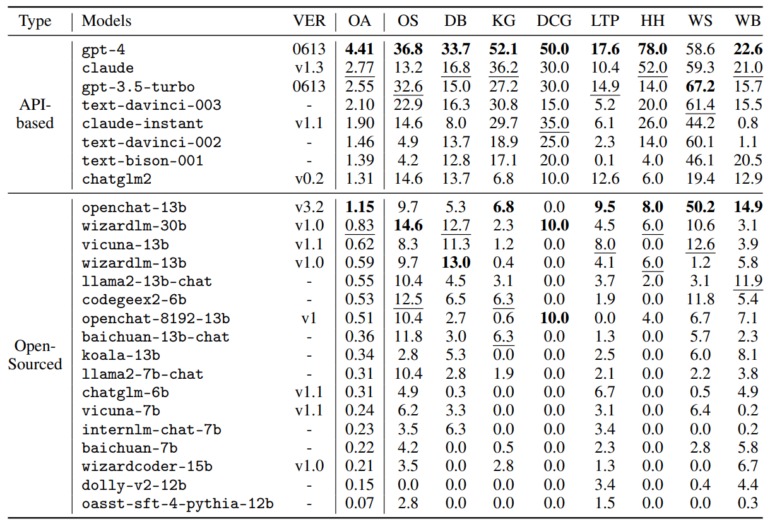
AgentBenchテストの結果、GPT-4は最高の総合スコア4.41を獲得し、ほぼすべての領域で優位性を示しました。ただし、WebショッピングのタスクではGPT-3.5がトップの成績を収めました。
競合他社の中では、AnthropicのClaudeモデルが総合スコア2.77でGPT-3.5 Turboモデルを上回りました。
Llama-13B ベースの OpenChat は、 1.15 ポイントで最もパフォーマンスの高い OS モデルです。
We unveil that while top LLMs are becoming capable of tackling complex real-world missions, for open-sourced competitiors there are still a long way to go.
From the paper
暫定結果リストには、Google の PaLM 2 やClaude 2、Aleph Alpha のモデルなどの多くの商用モデルや
他のオープンソース モデルが含まれていません。
研究チームは、より広範なパフォーマンス比較のために、Github 上の研究コミュニティが利用できるツールキット、データセット、ベンチマーク環境を作成しており、詳細とデモデータは、AgentBenchで入手できます。
GPT-4と他のモデルとのギャップ
オープンソースモデルの平均スコアはわずか 0.42 ポイントで、複雑なタスクにおいて失敗する傾向が見られました。これに対して、GPT-4は高いパフォーマンスを示し、創造的な問題解決能力においても優れた結果を残しました。一般的に、商用およびオープンソースモデルとGPT-4との性能ギャップは顕著であり、GPT-4が多くのタスクで優れた成果を上げていることが示されています。
今後の展望
研究者チームは、さらなる性能比較のためにGithub上で利用可能なツールキット、データセット、ベンチマーク環境を開発しています。これにより、研究コミュニティが異なる商用モデルやオープンソースモデルの性能を評価し、比較することが可能となります。
まとめ
AgentBenchテストによれば、GPT-4は「現実世界の実用的なミッション」において驚異的な成果を上げており、8つの異なる領域において高い実用性を示しています。競合他社を凌駕し、総合スコア4.41を獲得したGPT-4は、生成テキストAIの最先端を走っています。今後の展望として、より広範な性能比較が可能となるツールや環境が開発されることが期待されます。
よくある質問(FAQ)
- AgentBenchテストはどのように実施されましたか?
AgentBenchテストはリアルタイムの対話型環境で行われました。さまざまな領域においてAIモデルが実際のタスクを処理する能力を評価するためのテストです。 - GPT-4が他のモデルに優れている点は何ですか?
GPT-4は多くの領域で高い成果を上げましたが、特にその幅広い知識と問題解決能力が際立っています。 - なぜオープンソースモデルの性能が低いとされていますか?
オープンソースモデルは商用モデルに比べて性能が劣ることが一般的です。研究者らは、より高度なタスクにおいてオープンソースモデルが限界に達している可能性があります。 - 将来の展望について教えてください。
研究コミュニティはGithub上で利用可能なツールやデータセットを開発し、商用およびオープンソースモデルの性能比較を進める予定です。これにより、より客観的な評価が可能となるでしょう。 - GPT-4の優れた点を1つ挙げるとしたら何ですか?
GPT-4の最も優れた点は、多様なタスクにおいて高い適応能力を持っていることです。それにより、現実世界のさまざまなミッションに対応できる可能性が高まっています。