新しい手法により、トレーニング データを使用せずに安定した拡散が改善されました
安定拡散と強化学習の出会い – ノイズ除去拡散ポリシー最適化(DDPO)
人工知能(AI)の進化は、画像生成の分野において驚くべき進展をもたらしています。特に、拡散モデルと呼ばれる手法は、画像合成の標準となり、医薬品設計 や連続制御などの分野で利用されています。最新の研究では、トレーニングデータを使用せずに拡散モデルをより安定させる新しい手法が提案されました。この手法は、強化学習との組み合わせによって、画像生成AIモデルのトレーニングを効果的に行う方法を示しています。
強化学習による画像生成AIモデルの最適化
拡散モデルは、ランダムノイズを画像パターンに変換するプロセスです。従来のトレーニング方法では、拡散モデルはトレーニングデータからコンテンツを段階的に再構築することを学習していました。しかし、新しい研究では、強化学習を導入することで、拡散モデルをより効果的にトレーニングする方法を提案しています。これにより、特定の目標(例えば、画像の美的品質の向上)を達成するために生成AIモデルを微調整することが可能になります。
- 圧縮率: JPEG アルゴリズムを使用した画像の圧縮はどのくらい簡単ですか? 報酬は、JPEG として保存したときの画像のマイナスのファイル サイズ (KB 単位) です。
- 非圧縮性: JPEG アルゴリズムを使用して画像を圧縮するのはどのくらい難しいですか? 報酬は、JPEG として保存したときの画像の正のファイル サイズ (KB 単位) です。
- 美的品質: 画像は人間の目にどの程度美的に魅力的ですか? 報酬は、人間の好みに基づいて訓練されたニューラル ネットワークである LAION-AESTHETICSの出力です。
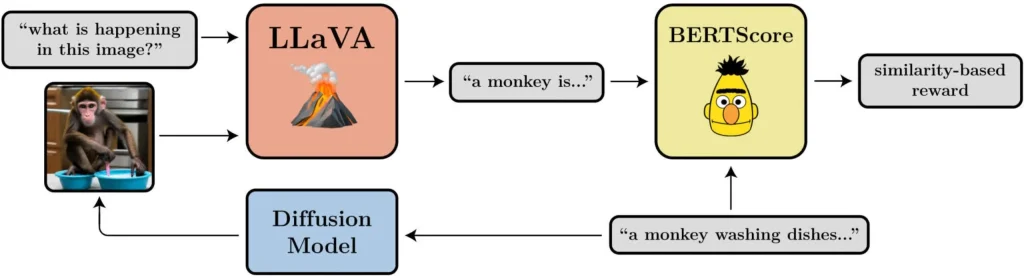
- プロンプトと画像の配置: 画像はプロンプトで要求された内容をどの程度表現していますか? これはもう少し複雑です。LLaVA に画像を入力し、LLaVA に画像の説明を依頼し、BERTScore を使用してその説明と元のプロンプトの類似性を計算します。
DDPOによる画像生成AIモデルの効果的な最適化
DDPOを使用した画像生成AIモデルの最適化は、さまざまなタスクにおいて成功を収めています。例えば、JPEGアルゴリズムを使用した画像の圧縮率の最適化や、美的品質の向上、プロンプトとの類似性の最適化などです。研究者たちは、DDPOがこれらのタスクを効果的に最適化できることを証明しました。

新たな可能性を切り開く手法
強化学習による画像生成AIモデルの最適化は、トレーニングデータの制約を取り除き、新たな可能性を切り開くものです。研究者たちは、「パターンマッチングを超えた方法で、トレーニングデータを必ずしも必要とせずに、拡散モデルを効果的にトレーニングする方法」を見つけたと述べています。この手法は、データの品質と創造性によってのみ制約されるため、さまざまな応用が可能です。
まとめ
新たな手法により、トレーニングデータを使用せずに安定した拡散が改善されました。強化学習を導入することで、画像生成AIモデルのトレーニングを効果的に行うことができます。DDPOという手法を使用することで、画像の圧縮率、非圧縮性、美的品質、およびプロンプトとの類似性の最適化が可能となりました。この手法は、トレーニングデータを必要とせずにモデルをトレーニングするため、新たな可能性を切り開くことができます。
複雑で高次元の出力を生成するという点では、拡散モデルに勝るものはありません。ただし、これまでのところ、大量のデータ (たとえば、画像とキャプションのペア) からパターンを学習することを目的とするアプリケーションでほとんど成功しています。私たちが発見したのは、パターン マッチングを超えた方法で、トレーニング データを必ずしも必要とせずに、拡散モデルを効果的にトレーニングする方法です。可能性は、報酬関数の品質と創造性によってのみ制限されます。
この作業での DDPO の使用方法は、言語モデルの微調整の最近の成功に触発されています。OpenAI の GPT モデルは、Stable Diffusion と同様に、まず大量のインターネット データでトレーニングされます。その後、RL で微調整されて、ChatGPT のような便利なツールが生成されます。通常、その報酬関数は人間の好みから学習されますが、最近では他の人も 学習しています。代わりに AI フィードバックに基づく報酬関数を使用して、強力なチャットボットを作成する方法を考え出しました。チャットボット体制と比較すると、私たちの実験は小規模であり、範囲も限られています。
さらに、「事前トレーニング + 微調整」パラダイムが DDPO を使用する唯一の方法ではありません。優れた報酬関数を持っている限り、最初から RL でトレーニングすることを妨げるものは何もありません。この設定はまだ開拓されていませんが、DDPO の強みが真に発揮される可能性がある場所です。Pure RL は、ゲームのプレイ からロボット操作、核融合、チップ設計 に至る まで、幅広い分野に長い間適用されてきました。拡散モデルの強力な表現力をミックスに加えることで、RL の既存のアプリケーションを次のレベルに引き上げ、さらには新しいアプリケーションを発見できる可能性があります。
引用:BAIR
論文:強化学習による拡散モデルのトレーニング
Kevin Black *、 Michael Janner *、 Yilun Du、 Ilya Kostrikov、およびSergey Levine
arXiv プレプリント。DDPO についてのPDF
よくある質問
Q1: DDPOを使用した画像生成AIモデルの最適化は、どのように行われますか?
A1: DDPOは強化学習を使用して行われます。研究者たちは、画像の圧縮率、非圧縮性、美的品質、およびプロンプトとの類似性を最適化するための報酬関数を設定し、それを最大化するようにモデルをトレーニングします。
Q2: DDPOを使用した最適化は、どのような応用がありますか?
A2: DDPOは、画像合成の分野においてさまざまな応用ができる可能性があります。
Q3: DDPOを使用した最適化は、トレーニングデータを必要としますか?
A3: DDPOはトレーニングデータを必要としません。この手法は、データの品質と創造性によってのみ制約されるため、トレーニングデータの量に制約されることなくモデルをトレーニングすることができます。
Q4: 新しい手法による画像生成AIモデルの最適化は、既存の手法と比べてどのような利点がありますか?
A4: 新しい手法は、トレーニングデータの制約を取り除き、より柔軟なトレーニングが可能です。また、画像の圧縮率、非圧縮性、美的品質、およびプロンプトとの類似性の最適化が効果的に行える点も利点と言えます。
Q5: 今後の研究はどのような課題に取り組む予定ですか?
A5: 今後の研究では、報酬の過剰最適化など、DDPOの課題に取り組む予定です。さらに、拡散モデルのトレーニングにおける安定性や信頼性の向上を目指していきます。