人工知能(AI)の世界は急速に進化し続けており、その中で強力な言語モデルの必要性も同様に高まっています。Allen Institute for AI(AI2)は、巨大なステップを踏み出し、Dolmaというオープンソースのデータセットを提供しました。このデータセットは、ウェブコンテンツ、科学論文、コード、書籍など多様な情報源から抽出された3兆トークンから成り立っています。これは、これまでに公に提供された中で最大のデータセットです。
Dolmaデータセットの概要
1. 巨大なステップの踏み出し
AI2は、言語モデルの進化に合わせて、Dolmaデータセットを提供しました。このステップは、AI技術の進化にとって画期的なものであり、AI2のリーダーシップを示しています。「最高のオープン言語モデル」を開発するという目標を念頭に置いた大規模な Dolma (OLMo に供給するデータ)データセットになります。
2. データの多様性
Dolmaは、多様な情報源からのデータを収集しています。ウェブコンテンツから科学論文、コード、書籍まで、幅広いテキストデータが含まれており、その豊富なデータの多様性がモデルの学習に貢献しています。
3. リリース予定のOLMo言語モデル
Dolmaは、2024年初頭にリリース予定の「Open Language Model(OLMo)」の基盤となっています。OLMoは、AI2が開発中の次世代の強力なオープン言語モデルであり、Dolmaデータセットがその訓練に活用される予定です。
Dolmaデータセットの特徴
1. 最大のオープンソースデータセット
Dolmaは、現在最大のオープンソースの言語データセットです。その大規模なサイズが、高度なモデルの構築と訓練に寄与しています。
2. 提供されるツールと再現性
Dolmaは、開発者や研究者に向けて、Hugging Faceを通じて提供されています。研究者はDolmaを活用するだけでなく、その結果の再現性を確保するためのツールも提供されています。
3. 英語データを中心とした構成
Dolmaは、主に英語データで構成されています。しかし、将来のバージョンでは他の言語も含まれる予定であり、多言語の情報源からのデータも利用できる可能性があります。

その後のステップで、研究者らはデータセットから重複、低品質のコンテンツ、機密情報を除去し、コード例の品質を向上させました。
Dolmaデータセットの発展と比較
1. データの取得源
Dolmaのデータは、ウェブデータに焦点を当てたCommon Crawlプロジェクトから取得されています。さらに、他の情報源としてC4コレクション、peS20の学術テキスト、The Stackのコードスニペット、Project Gutenbergの書籍、英語版ウィキペディアなども含まれています。
2. AI21の視点からの理想的なデータセット
AI21の視点から見た理想的なデータセットは、いくつかの基準を満たす必要があります
オープンさ、代表性、サイズ、再現性。特に個人に影響を及ぼす可能性のあるリスクも最小限に抑えるべきです。
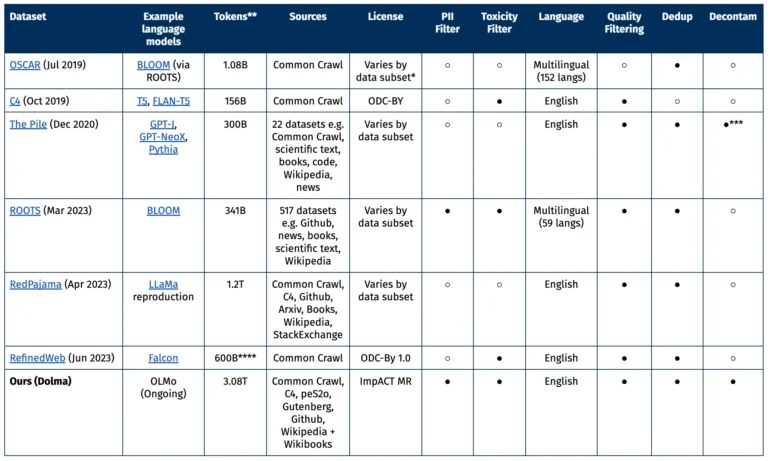
モデル内のパラメーターの数だけでなく、言語モデルの訓練資料の量も性能において中心的な役割を果たすことを示しています。
Dolmaデータセットの提供とオープンソースの問題
1. リリースとライセンス
DolmaデータセットはAI2のImpACTライセンスの下で提供されています。研究者は特定の要件を満たすために連絡先情報を提供したり、Dolmaの使用に同意したりする必要があります。個人データの削除も可能な仕組みが用意されています。
2. オープンソースへの議論
Dolmaにはオープンソースの議論も存在します。一部の批評家は、Dolmaがオープンではあるものの、オープンソースとは見なされないと主張しています。この議論は、オープンソースの定義や要件に対する考え方の違いに起因しています。
まとめと展望
Allen Institute for AI(AI2)は、Dolmaデータセットを通じて、言語モデルの発展と研究の進化を促進しています。このデータセットは、OLMo言語モデルの基盤となり、AI技術の更なる進化を支える重要な要素となるでしょう。Dolmaの提供により、AI研究者や開発者はより高度なモデルの構築と研究を行う新たな可能性を手にすることができます。
よくある質問(FAQs)
Q1: Dolmaデータセットはどのように利用できますか?
A1: DolmaデータセットはHugging Faceを通じて利用可能です。研究者や開発者はこのプラットフォームを通じてデータにアクセスし、モデルの訓練や研究に活用できます。
Q2: Dolmaは将来的に他言語のデータも含む予定ですか?
A2: はい、Dolmaは将来のバージョンで他の言語も含む予定です。初期バージョンでは英語データに焦点を当てていますが、多言語のデータも追加される予定です。
Q3: Dolmaのオープンソース性についてどのような議論がありますか?
A3: Dolmaのオープンソース性については議論があります。一部の意見では、Dolmaはオープンソースであるものの、オープンソースとは異なると主張しています。
Q4: Dolmaデータセットのリリース時期はいつですか?
A4: Dolmaデータセットは2024年初頭にリリース予定のOLMo言語モデルの基盤となっており、そのタイミングに合わせて提供される予定です。
Q5: Dolmaのデータはどのようにクリーニングされましたか?
A5: Dolmaのデータはさまざまな情報源からクリーンなテキスト文書に変換されました。重複や低品質なコンテンツ、機密情報は削除され、データの品質が向上しています。









